

End-to-End Data Pipeline Series: Tutorial 7 - Visualization

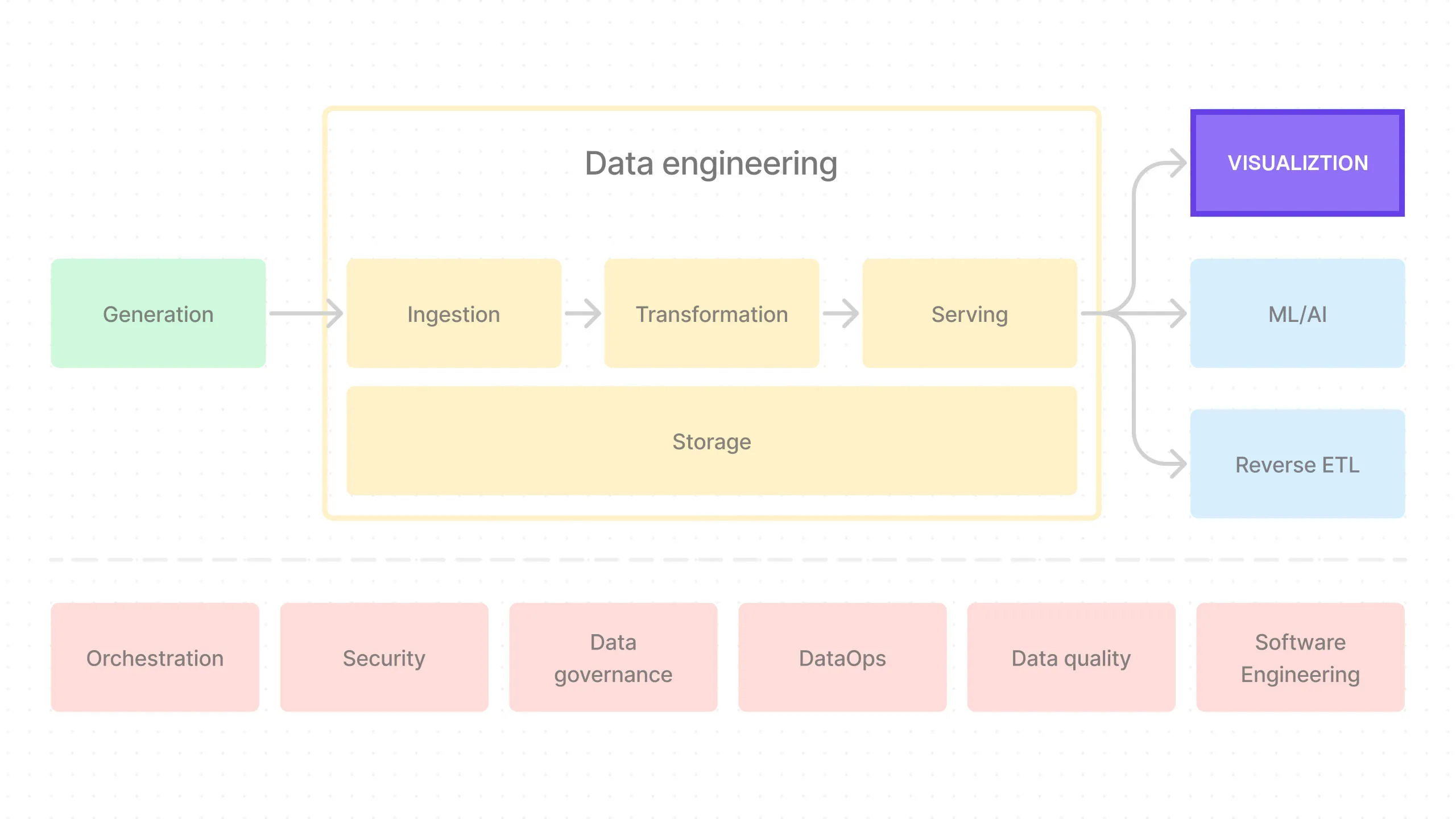
Welcome back! This is the sixth post in a series where we’ll build an end-to-end data pipeline together.
Here’s where we’re at:
- Introduction to End-to-End Data Pipeline
- Data Storage with MinIO/S3 and Apache Iceberg
- Data Ingestion with Meltano
- Data Transformation with DBT and Trino - Part 1
- Data Transformation with DBT and Trino - Part 2
- Data Orchestration with Dagster
- Data Visualization with Superset (this post)
- Building end-to-end data pipeline with Sidetrek
If you want to view the code for this series, you can find it here. To view the progress up to this post, you can check out the visualization branch.
Today, we’re going to finally visualize the data we’ve been working on in the previous posts using Superset.
What is Superset?
Superset is an open-source data exploration and visualization tool. Data analysts use Superset to create dashboards and reports.
It allows easy connection to various databases, data warehouses, and lakehouses, enabling data visualization without the need to write any code.
Other popular tools in this space include Metabase, Tableau, Looker, and PowerBI. But with the exception of Metabase, these tools are not open-source.
Install Superset
The easiest way to install Superset locally is to clone their GitHub repository.
First make sure you’re in the project root directory and run:
Then cd into the superset directory:
Add extra_hosts to the Docker Compose File
We’ll be using docker-compose-image-tag.yml to run Superset. We need to add an extra_hosts entry to the superset and superset-worker services in the docker-compose-image-tag.yml file.
This is because we’ll be connecting Trino to Superset, but because they’re not running in the same docker-compose file, we need a way for Superset to access Trino’s docker container.
Also, currently there’s a bug in Superset that doesn’t install trino package by default. So you’ll have to change the superset service command as well.
Let’s make all those changes:
services:
...
superset:
...
# command: ["/app/docker/docker-bootstrap.sh", "app-gunicorn"]
command: bash -c "pip install trino && /app/docker/docker-bootstrap.sh app-gunicorn"
extra_hosts:
- host.docker.internal:host-gateway
...
superset-worker:
...
extra_hosts:
- host.docker.internal:host-gateway
...Change Environment Variables
One more thing is to change a couple of environment variables in superset/docker/.env:
...
SUPERSET_ENV=production
SUPERSET_LOAD_EXAMPLES=no
...Remove .git Directory
We also need to remove the .git directory from the superset directory:
Because we cloned the Superset repository, git will complain about more than one git repository in our project.
Start Superset
Before we start Superset, make sure all other docker services are running.
In the project root directory, run:
Then cd into the superset directory:
We can now start Superset:
Now you can go to http://localhost:8088 and log in with the username admin and password admin.
Set Up Database Connection
Once you’re logged in, the first thing we need to do is connect Trino as a database connection so we can query the data.
- Go to http://localhost:8088/databaseview/list.
- Click on
+DATABASEand in the popup, selectTrinoin theSUPPORTED DATABASESdropdown inOr choose from a list of other databases we support:section. - In the field where it says
SQLALCHEMY URI, entertrino://trino@host.docker.internal:8080/iceberg. - Click
Connect.
You should now see “Trino” in the list of Databases.
One thing to note here is the use of host.docker.internal in the URI. This is because we’re running Superset in a Docker container and need to access the Trino container from the host machine.
Remember the extra_hosts we added to Superset’s docker-compose.yml file? This is where it comes into play.
If we were to run Superset in the same docker-compose.yaml file as the Trino container, we could’ve just used the container name as the hostname.
But since running Superset that way is unnecessarily complicated, we opted to run it in a separate container.
Add Datasets
- Go to http://localhost:8088/tablemodelview/list.
- Click on
+DATASET. - In the sidebar, select
Trinoasdatabase,project_martsasschemaandmarts_iceberg__generalastable. - Click on
CREATE DATASET AND CREATE CHART.
Add Charts
Before we can create a dashboard, we need to create the charts. We’re going to use these types of charts:
- Big Number
- Line Chart
- Pie Chart
- World Map
- Bar Chart
- Table
We’ll create the following charts:
- No. of Orders
- Total Sales
- No. of Customers
- No. of Countries
- No. of Orders Over Time
- Customer Acquisition by Traffic Source
- Customer Distribution by Country
- Average Customer Age by Gender
- Total Revenue by Category
- Payment Received by Payment Method
- Average Order Value Over Time
- Top 10 Highest Revenue Generating Referrers
Create the Charts
For each of the charts below, follow this process to create it:
- Go to http://localhost:8088/chart/add.
- Select the dataset and select a chart type, such as Bar Chart.
- Click on
CREATE NEW CHART. - Add Metrics, Filters, Dimensions, etc.
- Click on
UPDATE CHARTandSAVE. - On pop up, give a name to the chart and click on
SAVE.
OK let’s create the charts:
- No. of Orders
- Chart name: No. of Orders
- Type: Big Number
- Query:
- Filters:
order_created_at(No filter) - Metric (in Custom SQL tab):
COUNT(order_id)
- Filters:
- Description: The total number of orders.
- Total Sales
- Chart name: Total Sales
- Type: Big Number
- Query:
- Filters:
order_created_at(No filter) - Metric (in Custom SQL tab):
SUM(total_product_price)
- Filters:
- Description: The total sales generated.
- No. of Customers
- Chart name: No. of Customers
- Type: Big Number
- Query:
- Filters:
order_created_at(No filter) - Metric (in Custom SQL tab):
COUNT(DISTINCT customer_id)
- Filters:
- Description: The total number of customers.
- No. of Countries
- Chart name: No. of Countries
- Type: Big Number
- Query:
- Filters:
order_created_at(No filter) - Metric (in Custom SQL tab):
COUNT(DISTINCT country)
- Filters:
- Description: The total number of countries where customers are located.
- No. of Orders Over Time
- Chart name: No. of Orders Over Time
- Type: Line Chart
- Query:
- X-axis:
order_created_at - Time grain:
Month - Metric (in Custom SQL tab):
COUNT(order_id) - Filters:
order_created_at(No filter)
- X-axis:
- Description: The number of orders over time to visualize trends in order volume.
- Customer Acquisition by Traffic Source
- Chart name: Customer Acquisition by Traffic Source
- Type: Pie Chart
- Query:
- Dimension:
traffic_source - Metric (in Custom SQL tab):
COUNT(customer_id) - Filters:
order_created_at(No filter)
- Dimension:
- Description: How customers are finding your store by visualizing the number of customers acquired from different traffic sources.
- Customer Distribution by Country
- Chart name: Customer Distribution by Country
- Type: World Map
- Query:
- Country Column:
country - Country Field Type:
Full name - Metric (in Custom SQL tab):
COUNT(DISTINCT customer_id) - Filters:
order_created_at(No filter)
- Country Column:
- Description: The distribution of customers by country to understand the geographic spread of your customer base.
- Average Customer Age by Gender
- Chart name: Average Customer Age by Gender
- Type: Bar Chart
- Query:
- X-axis:
gender - Metric (in Custom SQL tab):
AVG(customer_age) - Contribution Mode:
None - Filters:
order_created_at(No filter)
- X-axis:
- Description: The customer ages by gender to understand the demographics of your customer base.
- Total Revenue by Category
- Chart name: Total Revenue by Category
- Type: Bar Chart
- Query:
- X-axis:
product_category - Metric (in Custom SQL tab):
SUM(total_product_price) - Filters:
order_created_at(No filter)
- X-axis:
- Description: The total sales for each product category to identify the top-selling categories.
- Payment Received by Payment Method
- Chart name: Payment Received by Payment Method
- Type: Pie Chart
- Query:
- Dimension:
payment_method - Metric (in Custom SQL tab):
SUM(total_price_with_tax) - Filters:
order_created_at(No filter)
- Dimension:
- Description: The total amount of payment received through payment methods.
- Average Order Value Over Time
- Chart name: Average Order Value Over Time
- Type: Line Chart
- Query:
- X-axis:
order_created_at - Time grain:
Day - Metric (in Custom SQL tab):
AVG(total_price_with_shipping) - Contribution Mode:
None - Filters:
order_created_at(No filter)
- X-axis:
- Description: The average order value over time to track changes in purchasing behavior.
- Top 10 Highest Revenue Generating Referrers
- Chart name: Top 10 Highest Revenue Generating Referrers
- Type: Table
- Query:
- Query Mode:
AGGREGATE - Dimension:
referrer - Metric (in Custom SQL tab):
SUM(total_product_price) - Filters:
order_created_at(No filter) - Row Limit:
10
- Query Mode:
- Description: The top 10 referrer with the highest total sales generated.
Create Dashboards
OK awesome - now that we have all the charts, let’s create a dashboard to visualize the data.
- Go to http://localhost:8088/dashboard/list.
- Click on
+DASHBOARD. - Give a title of the dashboard and drag and drop the charts you want to add to it.
- Finally, click on
SAVE.
Conclusion
And that’s it! We’ve successfully visualized the data using Superset.
That was quite a lot of work with many steps and gotchas.
We can condense all the steps into a couple of CLI commands using Sidetrek, which we’ll cover in the next post.
All Sidetrek is doing underneath is automating the steps we’ve done manually in this series so far.
In the next post, we’ll see how to use Sidetrek to automate the entire process of building and running an end-to-end data pipeline.
Stay tuned!
Questions and Feedback
If you have any questions or feedback, feel free to join us on Slack and we’ll do our best to help!