

End-to-End Data Pipeline Series: Tutorial 2 - Storage

Welcome to the second post in our series where we’ll build an end-to-end data pipeline from scratch!
Here’s where we are:
- Introduction to End-to-End Data Pipeline
- Data Storage with MinIO/S3 and Apache Iceberg (this post)
- Data Ingestion with Meltano
- Data Transformation with DBT and Trino - Part 1
- Data Transformation with DBT and Trino - Part 2
- Data Orchestration with Dagster
- Data Visualization with Superset
- Building end-to-end data pipeline with Sidetrek
In the previous post, we learned what a data pipeline is and how it works. We also looked at the big picture of how data flows from data sources to data consumers.
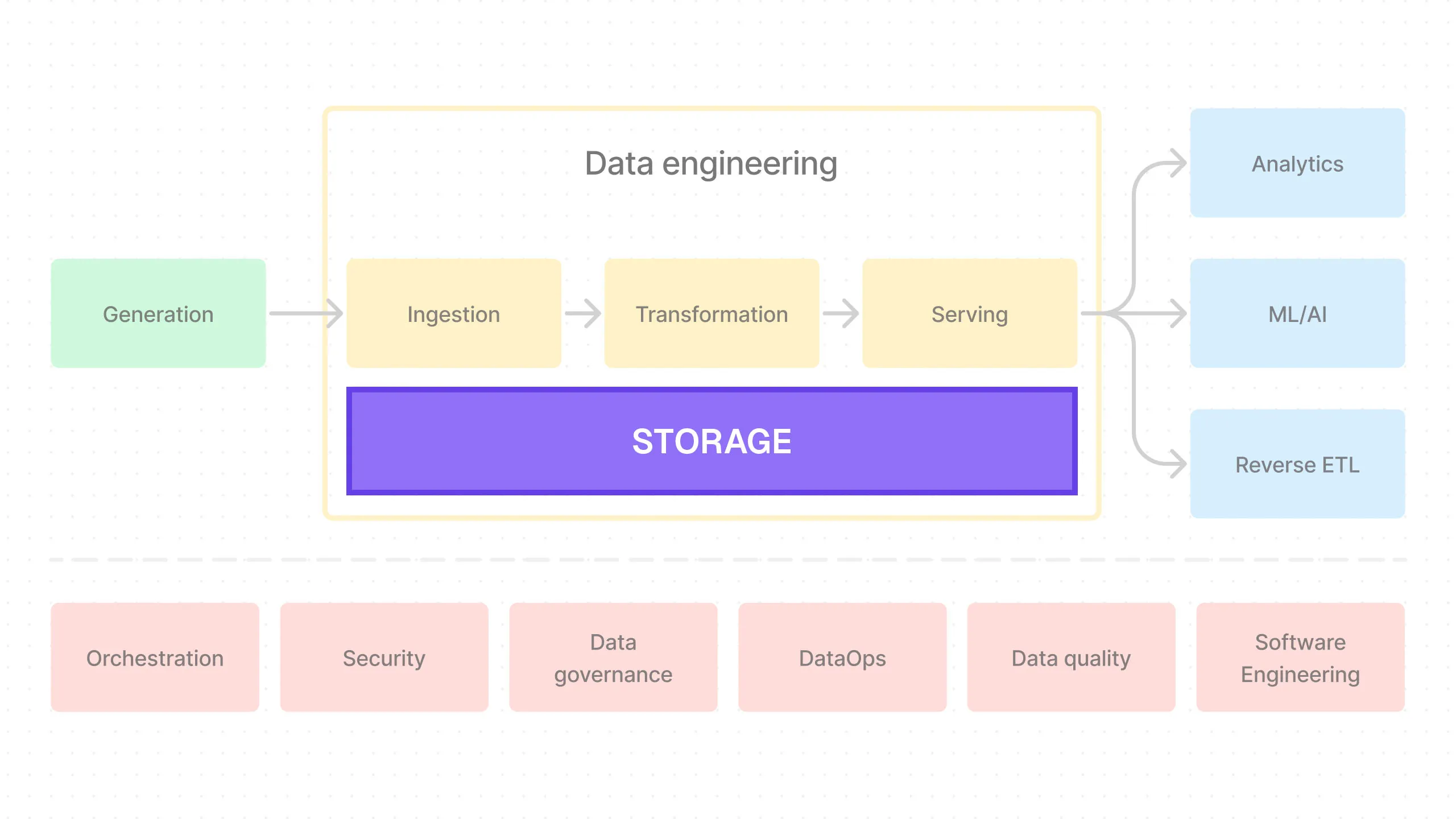
As a reminder, here’s our end-to-end data pipeline architecture for this series:
- Storage: MinIO (local replacement for S3) and Apache Iceberg
- Ingestion: Meltano
- Transformation: DBT for SQL building, Trino for querying
- Orchestration: Dagster
- Visualization: Superset
In this post, we’ll focus on the “Storage” part of the data pipeline, where we store the data that has been generated and ingested.
We’ll be using two technologies for this: MinIO and Apache Iceberg.
MinIO
MinIO is an object storage system, just like AWS S3.
So why can’t we just use s3? Because s3 doesn’t have a local version - it’s only available in the cloud. We need a storage solution that can replace s3 in our local development environment.
That’s where MinIO comes in. MinIO works entirely locally and offers a convenient Docker image that we can use to spin up an object storage system in our local environment.
The key point is that MinIO is “s3-compatible storage” - meaning it implements the S3 API, making it a drop-in replacement for s3 in our local environment. In other words, we can use MinIO just as if we were using s3, and everything should work exactly the same when we deploy our code to the cloud and swap MinIO for s3 in our production environment.
This is critical because we want our development environment to be as similar to our production environment as possible. Otherwise, even if everything works perfectly locally, things might break when we deploy to production.
This concept is known as “environment parity” or “dev/prod parity.” Without dev/prod parity, we have to worry every time we release to production because, even though everything works perfectly locally, it might break in a production environment.
We want to avoid this as much as possible. MinIO allows us to achieve dev/prod parity because it is S3-compatible storage.
Apache Iceberg
Apache Iceberg is a data lakehouse platform. More specifically, it’s an open-source table format designed for large-scale data analytics. It was initially developed by Netflix and later contributed to the Apache Software Foundation.
OK, let’s unpack what this means.
Analytical (Columnar) Data Store
The first thing to note is that Iceberg is designed for analytical workloads. This means it’s a columnar data store, optimized for analytical queries like aggregations. This is in contrast to row-based data stores like Postgres, which are optimized for transactional workloads.
Apache Iceberg is a Table Format
The second thing to note is the word “table format”. Iceberg is a table format. But what does that mean?
It means that Iceberg is not a storage system in itself. It does not store data in physical storage like S3 does. Instead, it sits on top of object storage like MinIO or S3 and provides a way to access the physically stored data as a table — similar to a normal database table.
For example, if you save a CSV file to s3, it’s saved as a file. There is no concept of tables like when you save something to a database. But if you add Iceberg on top of s3, you can access that CSV file as a table.
The only caveat with this example is that CSV is a row-based format. Iceberg can handle both row-based and columnar formats, but since we’ll be doing business analytics, we’ll be using a columnar file format like Parquet.
The key thing to remember is that Iceberg is not a physical storage system; it sits on top of one to provide a table format for accessing the data. This allows us to use SQL to query the data stored in object storage like S3.
In essence, Iceberg turns object storage like S3 (which is file-based) into a data warehouse — or more accurately, a data lakehouse.
Apache Iceberg is NOT a Query Engine
Finally, remember that MinIO + Iceberg is purely storage. Even though Iceberg adds a table format to allow us to use SQL, it is not a query engine, so it cannot execute queries. This nicely showcases the concept of the separation of compute and storage.
We need a query engine (compute) to actually pull the data out of MinIO + Iceberg (storage).
In this series, that query engine is Trino. We’ll look at that in more detail soon, but it’s important to have a clear distinction between compute and storage in your mind. Again, MinIO + Iceberg is just storage. Trino is just a compute engine — or a “query engine” in data engineering parlance. The storage simply stores the data; we need the query engine to query that data.
Why Apache Iceberg?
So why use Iceberg when you could just use something like Snowflake? There are a few significant benefits of Iceberg over data warehouses like Snowflake.
First, because it directly accesses object storage like S3, it is much less expensive compared to data warehouses. Object storage is one of the cheapest forms of physical storage, and Iceberg runs directly on top of it. This makes it very cost-effective, which is particularly important if you have a large amount of data to work with.
The second important benefit of Apache Iceberg is that it’s completely open-source. Solutions like Snowflake are proprietary, which comes with typical risks such as data lock-in and high costs — especially as your data volume grows. Iceberg is owned by the Apache Foundation and will always be an open standard. An open standard also has a significant integration advantage. Many popular tools like Spark, Trino, and StarRocks are integrating seamlessly with Iceberg for this very reason.
The third benefit is that, being an OLAP data store built specifically for handling very large data volumes, Iceberg is highly performant for analytical workloads on large datasets. We’re talking about a single table containing up to petabytes of data!
Project Setup
Before we set up MinIO, let’s do some prep work.
First, we need to set up our project. We’ll use poetry to do this. Let’s call the project e2e_bi_tutorial.
And then we’ll cd into the project directory.
Eventually, our project directory structure will look something like this:
e2e_bi_tutorial
├── .venv
├── superset
├── trino
└── e2e_bi_tutorial
├── dagster
├── data
├── dbt
└── meltanoYou might be wondering why the Superset and Trino directories are at the project root, while the Dagster, DBT, and Meltano directories are inside the inner e2e_bi_tutorial directory?
That’s because the inner project directory is where the “user code” goes. This is where we’ll be adding all our code.
The tools outside this inner project directory are required to run the project, but we won’t be writing any code there.
Git
At this point, you might want to initialize a git repository in your project directory.
You can go to Github and create a new repository with the name e2e_bi_tutorial. Follow the instructions in Github to push your empty Poetry project to the repository.
We’ve also created a Github repository as we built this project. You can find it here.
Each post in this series will have a corresponding branch in the repository. You can check out the branch for each post to see the code at that stage. For this post, the branch is storage.
The main branch will have the final code for the entire project.
Set up MinIO
OK now let’s set up MinIO. MinIO can be set up using Docker and Docker Compose.
First, create a docker-compose.yaml file in the root of your project directory.
Inside it, let’s add this code:
services:
minio:
image: minio/minio
container_name: minio
command: server --address "0.0.0.0:9000" --console-address "0.0.0.0:9001" /data
restart: always
environment:
- MINIO_ROOT_USER=${AWS_ACCESS_KEY_ID}
- MINIO_ROOT_PASSWORD=${AWS_SECRET_ACCESS_KEY}
- MINIO_DOMAIN=minio
ports:
- 9000:9000
- 9001:9001
volumes:
- minio_data:/data
networks:
shared_network:
aliases:
- ${LAKEHOUSE_NAME}.minio
mc:
image: minio/mc
container_name: mc
hostname: mc
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
entrypoint: >-
/bin/sh -c "
until (/usr/bin/mc config host add minio ${S3_ENDPOINT}
${AWS_ACCESS_KEY_ID} ${AWS_SECRET_ACCESS_KEY}) do echo ...waiting... &&
sleep 1; done;
/usr/bin/mc mb minio/${LAKEHOUSE_NAME};
/usr/bin/mc policy set public minio/${LAKEHOUSE_NAME};
tail -f /dev/null;
"
networks:
- shared_network
depends_on:
- minio
volumes:
minio_data: null
networks:
shared_network:
driver: bridgeIf you’re not familiar with Docker Compose, it basically allows you to define and run multiple Docker containers simultaneously.
As you can see, we’ve added two separate docker services above: minio and mc.
Let’s first look at the minio service.
MinIO Service
The minio service is the MinIO server itself. We’re using the official MinIO Docker image.
We’ve set up the MinIO server to run on port 9000 and the MinIO console to run on port 9001. The “console” here is simply a web-based UI for MinIO. Later, when we run docker compose, you’ll be able to see the MinIO console in your browser at http://localhost:9001.
Then you should see the environment variables MINIO_ROOT_USER and MINIO_ROOT_PASSWORD. These are the credentials you’ll use to log in to the MinIO console. We’re using the same credentials as AWS here.
MINIO_DOMAIN is required to enable Virtual Host-style requests to the MinIO deployment for Iceberg. See the MinIO documentation for more information.
Finally, we’ve set up a volume called minio_data to store the MinIO data. This is where the actual data will be stored on our local hard drive.
mc Service
The mc service is the MinIO client. We’re using the official MinIO client Docker image.
Why do we need this? Because we need to create a default bucket in MinIO (we’re doing this in the entrypoint section of the mc service).
Without this, you’d have to manually create a bucket inside the MinIO console every time you destroy and recreate the docker containers.
One thing you might have noticed is the depends_on field. Since the mc service depends on the minio service, we’re telling Docker Compose to wait until the minio service is up and running before starting the mc service.
Required Environment Variables
You’ll notice that there are some environment variables we’re referencing in docker-compose.yaml:
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESSS3_ENDPOINTLAKEHOUSE_NAME
We’ll have to add this to our .env file. Create a .env file in the root of your project directory and add the following:
AWS_ACCESS_KEY_ID=admin
AWS_SECRET_ACCESS_KEY=admin_secret
LAKEHOUSE_NAME=lakehouse
S3_ENDPOINT=http://minio:9000.gitignore
Just so we don’t forget, we should add .env file to your .gitignore file to avoid accidentally committing your credentials to your repository.
Create .gitignore in the root of your project directory and add the following:
.env*For real use cases though, you might want to use the standard .gitignore file provided by Github. It’ll cover most of the common files you want to ignore.
Run docker compose
Now let’s run the docker containers:
It might take a while the first time you run it. Once it’s running, you can go to the MinIO console at http://localhost:9001 in your browser and log in with the credentials admin and admin_secret.
Once you do, you should see the bucket lakehouse already created in the MinIO console.
That’s it for MinIO!
Network
One quick thing you might have noticed is shared_network. This is a docker compose feature that lets services talk to each other.
If you want to learn more, feel free to look it up.
Set up Apache Iceberg
There are two things we need to set up to run Iceberg: 1) the Iceberg REST Catalog and 2) the Iceberg Postgres Catalog.
Iceberg REST Catalog
In simple terms, an Iceberg Catalog maintains a list of tables and their related metadata that points to the correct physical data.
It’s the entry point into Iceberg tables when you try to query them.
In reality, it is a lot more than that - it enables some of the core features of Iceberg like ACID transactions, for example. The details of Iceberg Catalogs are outside the scope of this post, but if you want to learn more, here’s an article that dives in deeper.
There are many catalog implementations available for Iceberg, such as Hive Metastore, AWS Glue, DynamoDB, etc.
But the REST Catalog is unique in that it serves as a universal interface that can connect to any catalog. This was developed as a solution for diverging implementations of different catalogs in the Iceberg ecosystem.
The REST catalog is quickly evolving, but the idea is for all catalogs to interface through this single REST specification, so we’ll be using it in our series.
Iceberg Postgres Catalog
Since the REST catalog is just an interface for another catalog, we need a physical catalog (a database) to store the Iceberg metadata.
We’ll be using Postgres for this.
Why Postgres? Because it’s a popular open-source database that’s easy to set up and use.
If you have a different use case, you may want to switch this out for a different database, as different catalogs have different performance characteristics for different use cases.
But for our purposes, Postgres will work just fine.
Set Up Iceberg REST Catalog
Let’s add Iceberg REST Catalog service to our docker-compose.yaml:
services:
minio:
...
mc:
...
iceberg-rest:
image: tabulario/iceberg-rest
container_name: iceberg_rest
ports:
- 8181:8181
environment:
- AWS_REGION=${AWS_REGION}
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- CATALOG_WAREHOUSE=s3a://${LAKEHOUSE_NAME}/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=${S3_ENDPOINT}
- CATALOG_CATALOG__IMPL=org.apache.iceberg.jdbc.JdbcCatalog
- CATALOG_URI=jdbc:postgresql://iceberg-pg-catalog:5432/${ICEBERG_PG_CATALOG_DB}
- CATALOG_JDBC_USER=${ICEBERG_PG_CATALOG_USER}
- CATALOG_JDBC_PASSWORD=${ICEBERG_PG_CATALOG_PASSWORD}
networks:
- shared_network
depends_on:
iceberg-pg-catalog:
condition: service_healthy
restart: true
...We’re using the tabulario/iceberg-rest Docker image from Tabular for the Iceberg REST Catalog.
Notice the additional environment variables we’ve added:
AWS_REGION: The aws region where the MinIO server is running.CATALOG_WAREHOUSE: The s3a url of the MinIO bucket we created earlier.CATALOG_IO__IMPL: The implementation of the IO interface. We’re using the S3FileIO implementation.CATALOG_S3_ENDPOINT: The endpoint of the S3 server. This is the url of the MinIO server we set up earlier.CATALOG_CATALOG__IMPL: The implementation of the catalog interface. We’re using the JdbcCatalog implementation which can connect to Postgres.CATALOG_URI: This is the URI of the Postgres catalog. We’re using the JDBC URI format to connect to the Postgres catalog.CATALOG_JDBC_USER: The username for the Postgres catalog.CATALOG_JDBC_PASSWORD: The password for the Postgres catalog.
Set Up Iceberg Postgres Catalog
Let’s add Iceberg Postgres Catalog to docker-compose.yaml:
services:
minio:
...
mc:
...
iceberg-rest:
...
iceberg-pg-catalog:
image: postgres:15-alpine
container_name: iceberg_pg_catalog
environment:
- POSTGRES_USER=${ICEBERG_PG_CATALOG_USER}
- POSTGRES_PASSWORD=${ICEBERG_PG_CATALOG_PASSWORD}
- POSTGRES_DB=${ICEBERG_PG_CATALOG_DB}
healthcheck:
test:
- CMD
- pg_isready
- -U
- ${ICEBERG_PG_CATALOG_USER}
interval: 5s
retries: 5
ports:
- 5433:5432
volumes:
- iceberg_pg_catalog_data:/var/lib/postgresql/data
networks:
- shared_network
...This is a simple Postgres service.
The only thing worth mentioning here is the healthcheck section. This is a Docker feature that lets you check if a service is healthy. In this case, we’re using the pg_isready command to check if the Postgres service is up and running.
This is required because the Iceberg REST Catalog service depends on the Postgres service. We’re telling Docker Compose to wait until the Postgres service is healthy before starting the Iceberg REST Catalog service.
Finally we need to add the volume:
services:
...
volumes:
...
iceberg_pg_catalog_data: null
...Environment Variables
We need to add the following environment variables to our .env file:
AWS_REGION=us-west-2
ICEBERG_CATALOG_NAME=icebergcatalog
ICEBERG_PG_CATALOG_USER=iceberg
ICEBERG_PG_CATALOG_PASSWORD=iceberg
ICEBERG_PG_CATALOG_DB=icebergRun docker compose
Now let’s run the docker containers:
Once it’s running, you should be able to see that all the docker containers running in Docker Desktop.
If you don’t have Docker Desktop, you can still view the running containers by running:
You should see the minio, mc, iceberg-rest, and iceberg-pg-catalog services running successfully.
That’s it for Iceberg! I know it was quite a lot to take in, so great job following along!
Query Engine
We can’t currently query Apache Iceberg. We need a query engine to do that (Trino in our case).
We’ll get to that in our “Transformation” post.
Clean Up
You can shut down the containers now:
Conclusion
In this post, we set up the storage part of our data pipeline using MinIO and Apache Iceberg.
MinIO is an object storage system that is s3-compatible and can be used as a local replacement for s3.
Apache Iceberg is a table format that sits on top of object storage and provides a way to access the physically stored data as a table - just like you would with a database or a data warehouse.
We saw how to set up MinIO and Iceberg using Docker and Docker Compose.
In the next post, we’ll set up Meltano for data ingestion.
Stay tuned!
Questions and Feedback
If you have any questions or feedback, feel free to join us on Slack and we’ll do our best to help!