

End-to-End Data Pipeline Series: Tutorial 4 - Transformation - Part 1

Hi all!
This is the fourth post in a series where we’ll build an end-to-end data pipeline together from scratch.
We’re already more than half way through!
- Introduction to End-to-End Data Pipeline
- Data Storage with MinIO/S3 and Apache Iceberg
- Data Ingestion with Meltano
- Data Transformation with DBT and Trino - Part 1 (this post)
- Data Transformation with DBT and Trino - Part 2
- Data Orchestration with Dagster
- Data Visualization with Superset
- Building end-to-end data pipeline with Sidetrek
If you want to view the code for this series, you can find it here. To view the progress up to this post, you can check out the transformation branch.
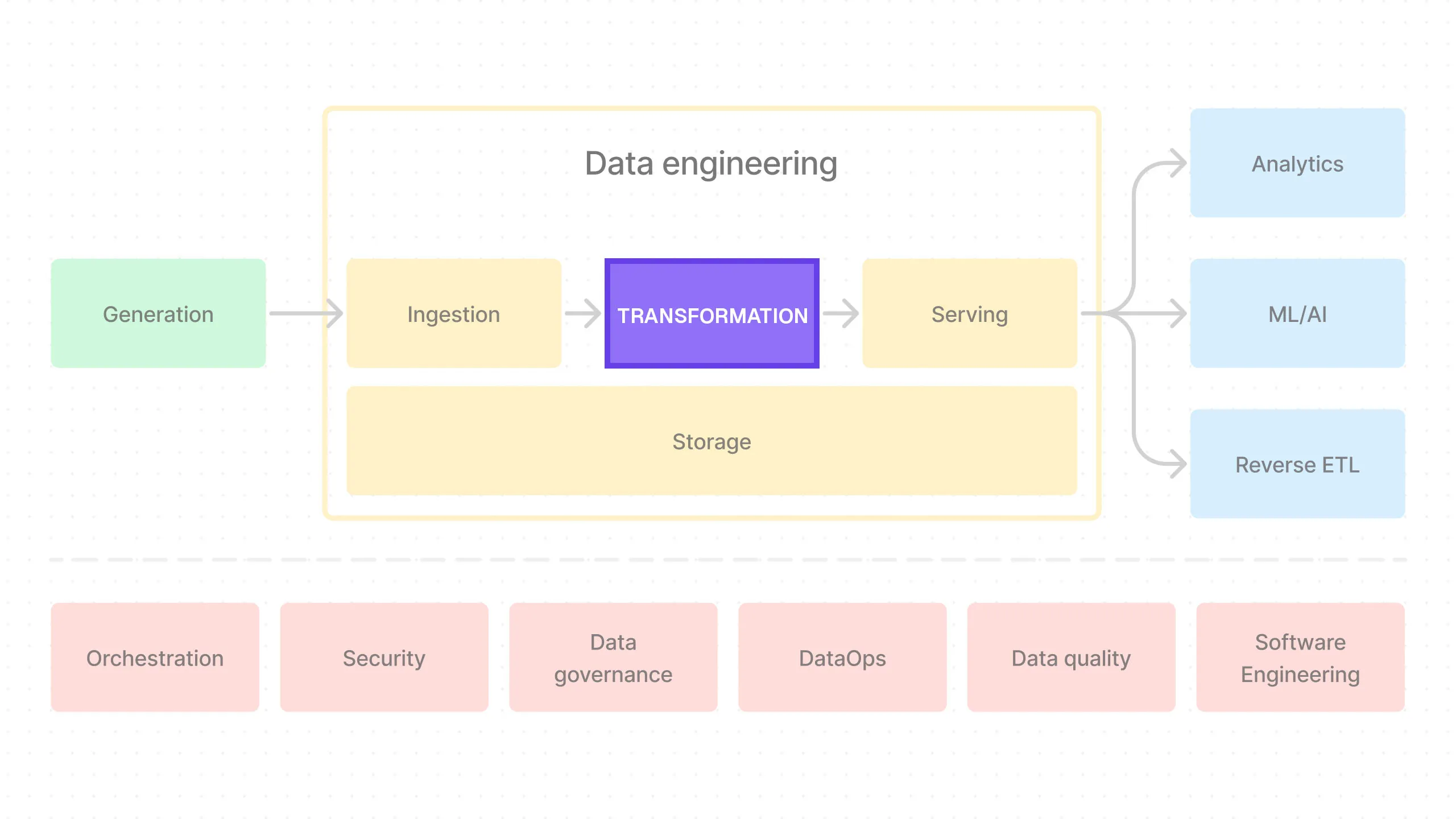
Today, we’re going to work on the transformation part of the pipeline.
What is Transformation?
Transformation is the process of changing data from its raw source form to something more useful for our data consumers.
An example might be joining two tables. For instance, we might have a customers table and an orders table. We can join these two tables to create a new table that contains both customer information and order information. This would make it much easier for our business analysts to visualize the data.
Another example might be data cleaning. For instance, we might have a column that contains missing values. We can clean the data by filling in the missing values with a default value or by removing the rows with missing values.
This is the T (transform) part of the ELT/ETL process.
DBT
DBT is an open-source tool that makes it easier to write transformation code in SQL.
DBT allows you to write transformations in SQL, which are then run against the connected data warehouse — in our case, the Iceberg lakehouse. It treats these transformations as code, meaning they can be version-controlled, peer-reviewed, and tested just like software code. This is very powerful.
Another useful feature of DBT is that it allows us to write modular SQL queries, enabling code reuse across different transformations. This makes our SQL code more reusable, maintainable, and less error-prone. It does this by using the Jinja templating language. We’ll dive deeper into this when we start coding.
Now, it’s important to note that DBT is NOT a query engine and cannot execute the SQL queries itself. To actually execute the SQL queries written in DBT, you need to connect it to a query engine like Trino — DBT calls this kind of connector an “adapter.”
So let’s talk about Trino.
Trino
Trino is an open-source distributed SQL query engine for large-scale data. Originally developed by Facebook and known as Presto, Trino was rebranded following a fork of the original Presto codebase.
It’s also known as a federated query engine.
Let’s unpack it and see what this means.
Query Engine
The first thing to notice here is that Trino is a query engine. We touched on this when we discussed Iceberg in the Storage post, but S3 + Iceberg is just storage. It stores the data, but we need some kind of compute engine to actually execute data queries. Trino is that compute engine. Since it’s specifically designed to query tabular data, we call it a “query engine”.
So to summarize: the physical data is stored in S3, Iceberg turns these files in S3 into tables, and then Trino is used to actually execute SQL queries on these tables to retrieve the data.
Distributed Query Engine
The next thing to note is the “distributed” part. Trino is a distributed query engine for large-scale data. This means it can use many machines simultaneously to execute SQL queries in parallel, making the queries much faster on large datasets.
Federated Query Engine
Finally, Trino is a federated query engine. That means it can connect to many different types of storage.
This is where Trino really shines — it’s already done the heavy lifting of creating connections to different storage systems, so we can just use them.
For example, we can use Trino to query data from our Iceberg lakehouse, but we can also use Trino to query data from Snowflake, BigQuery, Postgres, MongoDB, Elasticsearch, and even Google Sheets. Trino calls these connections “Connectors.”
Why Trino?
Now, you should know that there are many different query engines out there.
The most popular one is probably Apache Spark. We could easily replace Trino with Spark for our use case as well, although the usage is quite different.
Spark is arguably more complex to code than SQL, but it is also more flexible. In our opinion, Spark is also a bit harder to set up.
How DBT, Trino, and Iceberg Work Together
So at a high level, this is how it works: we use the dbt-trino adapter to allow us to execute DBT using our query engine, Trino.
Trino, in turn, is connected to our Iceberg lakehouse using the trino-iceberg connector so it can query our stored data.
In the end, our workflow is: we write our SQL queries in DBT, and then Trino executes them against our Iceberg lakehouse.
If this is a bit confusing right now, don’t worry - you’ll see all this in action as we implement them in code, and everything will become clearer.
Set Up Trino via Docker/Docker Compose
Before we set up Trino, here’s a quick review of the project directory structure we’ll be building:
e2e_bi_tutorial
├── .venv
├── superset
├── trino
└── e2e_bi_tutorial
├── dagster
├── data
├── dbt
└── meltanoLet’s add Trino to our docker-compose.yaml file.
services:
minio:
...
mc:
...
iceberg-rest:
...
iceberg-pg-catalog:
...
trino:
image: trinodb/trino:437
container_name: trino
ports:
- 8080:8080
environment:
- AWS_REGION=${AWS_REGION}
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- S3_ENDPOINT=${S3_ENDPOINT}
- LAKEHOUSE_NAME=${LAKEHOUSE_NAME}
volumes:
- ./trino/etc:/etc/trino
networks:
- shared_network
depends_on:
- minioNothing we haven’t seen before. We’re using the Trino’s official trinodb/trino:437 docker image, exposing port 8080, and setting up the environment variables.
The only thing is we’re adding a volume for Trino configurations. As you can see, we’re mounting the ./trino/etc directory to /etc/trino in the container.
Now, let’s create the trino directory and add the configurations.
Add Trino Configurations
First create the trino directory (make sure you’re in the project root first!).
We’re creating the trino directory and then etc and catalog directories inside it.
Then we need to add the following configuration files.
node.environment=development-server
-Xmx16G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-Dfile.encoding=UTF-8
# Reduce starvation of threads by GClocker, recommend to set about the number of cpu cores (JDK-8192647)
-XX:+UnlockDiagnosticVMOptions
-XX:GCLockerRetryAllocationCount=32Note: The -Xmx16G flag sets the maximum heap memory size to 16GB here. That’s the memory requirement for your machine.
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
discovery.uri=http://trino:8080connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://iceberg-rest:8181/
iceberg.rest-catalog.warehouse=s3a://${ENV:LAKEHOUSE_NAME}
hive.s3.aws-access-key=${ENV:AWS_ACCESS_KEY_ID}
hive.s3.aws-secret-key=${ENV:AWS_SECRET_ACCESS_KEY}
hive.s3.region=${ENV:AWS_REGION}
hive.s3.endpoint=${ENV:S3_ENDPOINT}
hive.s3.path-style-access=trueWe won’t go into detail on most of these configuration files since we’re following the recommended configurations from the Trino documentation.
The important bit here is trino/etc/catalog/iceberg.properties. This is where we connect Trino to Iceberg.
We’re setting the connector.name to iceberg and you can see that we’re setting the iceberg.catalog.type to rest (for “Iceberg REST catalog”). Then we set the iceberg.rest-catalog.uri to http://iceberg-rest:8181/ which is the path to the iceberg-rest docker service we set up in the previous post.
The tricky part here is that aws credentials, region, endpoint use the hive configuration variables. This tripped me up for a while, but this is how Trino connects to Iceberg.
Another gotcha is hive.s3.path-style-access=true configuration. Honestly, I never dug into the details, but Trino won’t be able to connect to Iceberg without this configuration.
Trino Shell
Now that we have our query engine Trino set up, we can finally use it to query our Iceberg tables!
Before we do any of that though, let’s make sure all our docker services are running:
Now we can enter the Trino Shell:
This will open the Trino shell where you can run SQL queries against your Iceberg tables.
Let’s see what catalogs we have:
Catalog
---------
iceberg
system
(2 rows)You should see iceberg in the list of catalogs.
Let’s see if we can view the schemas in the iceberg catalog:
Schema
--------------------
information_schema
raw
(2 rows)Awesome - we can see the raw schema. But where does this raw schema come from?
It’s from Meltano’s target-iceberg configuration. If you look at meltano.yml in Meltano project directory, you’ll find the field iceberg_catalog_namespace_name which is set to raw. This is where the raw schema comes from.
Can we view the tables? We already ran the ingestion and confirmed that the tables are created in MinIO (directories orders, products, etc). So we should be able to query the tables now.
To do that, first we set the schema to raw:
Then we can query the tables:
Table
-----------
customers
orders
products
stores
(4 rows)Nice!
Can we query what’s in the tables too? Sure, why not?
id | created_at | qty | product_id | customer_id | store_id | ...
----+-------------------------+-----+------------+-------------+----------+ ...
0 | 2023-12-08 00:00:00.000 | 2 | 1051 | 5355 | 10 | ...
1 | 2023-12-06 00:00:00.000 | 7 | 1623 | 8523 | 139 | ...
2 | 2023-12-08 00:00:00.000 | 3 | 8 | 7611 | 82 | ...
3 | 2023-03-24 00:00:00.000 | 7 | 823 | 19952 | 184 | ...
4 | 2022-11-01 00:00:00.000 | 9 | 350 | 7885 | 129 | ...
(5 rows)Great - finally we can query our Iceberg tables!
To exit the Trino CLI, simply type:
Now we can set up DBT and connect Trino to it to transform the data, but the post is getting really long, so let’s continue in the next post.
Clean Up
You can stop and remove all the docker services:
Conclusion
In this post, we set up Trino, connected it to Iceberg, and finally queries the Iceberg tables using Trino shell.
In the next post, we’ll set up DBT, connect it to Trino, and start writing SQL queries (i.e. DBT models) to transform the data.
See you soon!
Questions and Feedback
If you have any questions or feedback, feel free to join us on Slack and we’ll do our best to help!