

End-to-End Data Pipeline Series: Tutorial 5 - Transformation - Part 2

Welcome back!
This is the fifth post in a series where we’ll build an end-to-end data pipeline together from scratch.
We’re already more than half way through!
- Introduction to End-to-End Data Pipeline
- Data Storage with MinIO/S3 and Apache Iceberg
- Data Ingestion with Meltano
- Data Transformation with DBT and Trino - Part 1
- Data Transformation with DBT and Trino - Part 2 (this post)
- Data Orchestration with Dagster
- Data Visualization with Superset
- Building end-to-end data pipeline with Sidetrek
If you want to view the code for this series, you can find it here. To view the progress up to this post, you can check out the transformation branch.
Today, we’re going to continue our work on the transformation part of the pipeline.
Set Up DBT and Trino Adapter
We set up Trino in our last post, so we can now set up DBT and the Trino adapter.
Before we set up the adapter though, here’s a quick review of the project directory structure we’ll be building:
e2e_bi_tutorial
├── .venv
├── superset
├── trino
└── e2e_bi_tutorial
├── dagster
├── data
├── dbt
└── meltanoInstall DBT
We can install DBT with poetry add dbt-core and dbt-trino, but we already did that!
Because of the outstanding bug with Meltano + DBT, DBT needs to be installed before Meltano, so we already installed DBT in the Ingestion part of the series.
So there’s nothing to do here!
Initialize a DBT Project
Now we need to initialize a DBT project. Let’s first cd into the inner project directory (make sure you’re in project root first!).
So from the project root, run:
Then we need to create a dbt directory:
Let’s now cd into it:
Finally, to initialize a DBT project, run:
This will create a new DBT project in the dbt directory.
Remove the Default DBT Example Code
We don’t need the default example code that DBT creates for us. Let’s remove it:
Set Up DBT Trino Profile
Now we need to set up the DBT’s Trino profile.
First cd into the e2e_bi_tutorial directory (inside dbt project directory - where you should be if you’ve been following the tutorial):
Then create a new profile:
And then add the following configuration:
dbt_project:
target: trino
outputs:
trino:
type: trino
user: trino
host: localhost
port: 8080
database: iceberg
schema: project
http_scheme: http
threads: 1
session_properties:
query_max_run_time: 5dThe important parts here are:
type: trino- this tells DBT to use the Trino adapter.host: localhost- this is the host where Trino is running. Since we’re running Trino in a Docker container, we can uselocalhost.port: 8080- this is the port where Trino is running.database: iceberg- this is the database in Trino where we want to run our queries.schema: project- this tells DBT that we’ll be usingprojectas a prefix for our future schemas. See the DBT documentation for more information on this.
Update dbt_project.yml File
We also need to update the dbt_project.yml file to use the Trino adapter and set up our models.
You should see this file in the same directory as profiles.yml.
...
profile: dbt_project
...
on-run-start:
- CREATE SCHEMA IF NOT EXISTS raw
- CREATE SCHEMA IF NOT EXISTS {{ schema }}The important parts are:
profile: this tells DBT to use the Trino adapter.on-run-start: Trino schemas need to be created first before we can run DBT models inside them. We could do that manually, but it’s much better to add these commands since it ensures that all schemas we create in DBT are also automatically created in Trino.
Create DBT Models
OK, now we’ve set up all the tools required to write our transformation queries in DBT.
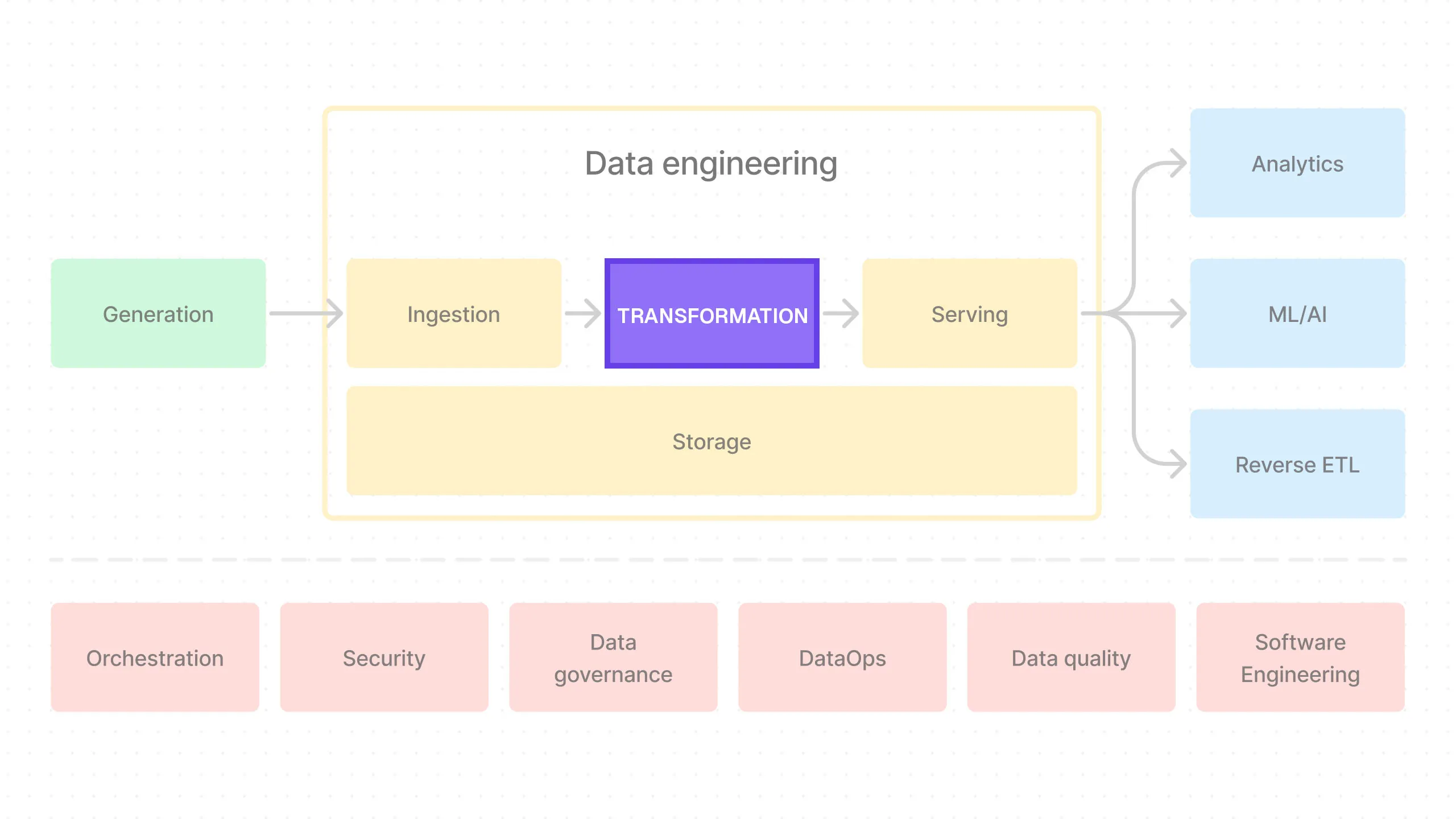
We could start writing SQL queries in DBT now, but instead, let’s first take a look at a helpful organizational pattern: Staging, Intermediate, and Marts.
Three Stages of Data Transformation - Staging, Intermediate, and Marts
This is a common pattern in data warehousing where you have three layers of transformations, progressively turning raw data into a more business-conformed form suitable for analytics.
The names Staging, Intermediate, and Marts come from DBT’s excellent Best Practices Guide (which we highly recommend you check out), but there are other similar ones like Databricks’ Medallion architecture (Bronze, Silver, Gold). It’s all the same idea.
This pattern not only makes our SQL code more modular and maintainable but also makes it easier to collaborate with others. With a common design pattern like this, everyone knows exactly what to expect.
- Staging: This is where we create atomic tables from the raw data. You can think of each of these tables as the most basic unit of data — an atomic building block that we’ll later compose together to build more complex SQL queries. This makes our SQL code more modular.
- Intermediate: This is where we compose a bunch of atomic tables from the staging stage to create more complex tables. You can think of this stage as an intermediate step between the modular tables in the staging stage and the final, business-conformed tables in the Marts stage.
- Marts: This is where you have the final, business-conformed data ready for analytics. Each mart is typically designed to be consumed by a specific function in the business, such as the finance team, marketing team, etc.
OK, now let’s take a look at how we can set up each stage.
Staging Models
In dbt/e2e_bi_tutorial/models directory, create 3 new directories: staging, intermediate, and marts.
Inside the staging directory, create a stg_iceberg.yml. This is where we specify the data sources as well as define the tables (or “models” in DBT terms) for the staging stage.
version: 2
sources:
- name: stg_iceberg
database: iceberg
schema: raw
tables:
- name: orders
- name: customers
- name: products
- name: stores
models:
- name: stg_iceberg__orders
- name: stg_iceberg__customers
- name: stg_iceberg__products
- name: stg_iceberg__storesNotice the sources with the database iceberg and the schema raw. This is because we’ve set up Trino to connect to Iceberg catalog (do not confuse this with Iceberg “catalog” - this is Trino “catalog”, or connector, called iceberg) in the raw schema.
If you recall, this is how we accessed Iceberg tables via Trino shell before (e.g. use iceberg.raw;).
In other words, database here maps to Trino catalog. Again, be careful not to confuse this with Iceberg “catalog” (i.e. Iceberg REST catalog) - this is Trino “catalog”, which is the what Trino calls its connectors.
The tables in sources specify the tables in the raw schema of the Iceberg catalog that we want to ingest.
Staging tables we want to create are then defined under models.
Note the DBT file naming convention
Staging DBT Models
Now let’s add the actual models!
Here’s the stg_iceberg__orders DBT model.
{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
incremental_strategy='merge',
unique_key='order_id',
properties={
"format": "'PARQUET'",
"sorted_by": "ARRAY['order_id']",
}
)
}}
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'orders') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS order_id,
CAST(created_at AS TIMESTAMP) AS order_created_at,
CAST(qty AS DECIMAL) AS qty,
CAST(product_id AS VARCHAR) AS product_id,
CAST(customer_id AS VARCHAR) AS customer_id,
CAST(store_id AS VARCHAR) AS store_id
from source
where row_num = 1
)
select * from deduped_and_renamedI’m sure you recognize the SQL queries here. The part you might not be familiar with is the config block at the top.
This is actually a Jinja template that DBT uses to augment SQL code. In this case, we’re telling DBT how to materialize this model (i.e. incremental with merge strategy) as well as Iceberg specific configurations like file_format (iceberg) and properties (what file format are we using to save the model in the physical object storage and what the sorting strategy is).
Why do we need unique_key? This is because we’re using incremental materialization. Without the unique_key parameter, this model would result in multiple rows in the target table. Instead, unique_key parameter ensures the existing row is updated instead.
When we run DBT build, it will take this code and generate a valid, standard-compliant SQL query that can be executed by Trino.
Adding Staging Model Configuration to dbt_project.yml
We also need to add a bit of extra configuration. We do this in the dbt_project.yml file in the dbt directory.
Update the models with the following:
...
models:
e2e_bi_tutorial:
staging:
+materialized: view
+schema: staging
+views_enabled: false
...The important parts are:
materialized: view- this tells DBT to materialize the model as a view. This is just default and is overwritten in our model SQL file inside theconfigfunction; recallmaterialized='incremental'. In fact,trino-icebergcurrently does not supportviews.schema: staging- this tells DBT to create the model in thestagingschema. Because we also specified the custom DBT schema in theprofiles.ymlfile, the final schema name created in Trino will beproject_staging.views_enabled: false- this tells DBT to not create views for the models. Again,trino-icebergdoes not currently support views.
Deduping
There’s one more thing we should go over: deduping.
Because target-iceberg currently only supports APPEND operation (this is due to current limitation of pyiceberg package), you will probably want to dedupe the data during the staging stage of the DBT transformation.
This way you can make sure the ingestion process is idempotent (i.e. you can run it multiple times with the same result).
There are many ways to dedupe your data here, but let’s see one way to do it.
Before we get to the code, let’s enter the Trino shell and see how many rows are in the raw orders table (i.e. ingested frmo Meltano before any transformation).
You’ll see that we have 100k rows in the raw orders table as expected (since our source orders.csv has 100k rows).
_col0
---------
1000000
(1 row)Once we run the staging DBT models, we can see that stg_iceberg__orders table also has 100k rows as expected.
NOTE: This won’t work for you now because we haven’t yet run dbt and create the stg_iceberg__orders table. But once you run the DBT models, you should see the same result.
The output should be:
_col0
---------
1000000
(1 row)Now, if we run the Meltano ingestion job AGAIN, we’ll see that the orders table in Trino will have 200k rows. This is because target-iceberg APPENDs the data.
You should see:
_col0
---------
2000000
(1 row)Clearly we don’t want this to happen in our staging model since we don’t want any duplicate data.
To dedupe the data, we add the row_num column to the source raw orders table by using the row_number() function in the stg_iceberg__orders model.
...
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'orders') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS order_id,
CAST(created_at AS TIMESTAMP) AS order_created_at,
CAST(qty AS DECIMAL) AS qty,
CAST(product_id AS VARCHAR) AS product_id,
CAST(customer_id AS VARCHAR) AS customer_id,
CAST(store_id AS VARCHAR) AS store_id
from source
where row_num = 1
)
select * from deduped_and_renamedThis code adds a row number to duplicate rows based on id field. For example, if we have two rows with the same id, the row with the higher id will have row_num of 1 and the other will have row_num of 2.
id | row_num
1 | 1
1 | 2
2 | 1
3 | 1Then in deduped_and_renamed CTE, we only select rows where row_num is 1. This effectively dedupes the data.
Now if you go back to the Trino shell and run the query to see the number of rows in the stg_iceberg__orders table, you’ll see that it’s still only 100k.
The output should be:
_col0
---------
1000000
(1 row)We can do this for all tables in the staging area to make sure our ingestion process is idempotent at the staging stage.
Add the Rest of the Staging Models
{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
incremental_strategy='merge',
unique_key='id',
properties={
"format": "'PARQUET'",
"partitioning": "ARRAY['traffic_source']",
"sorted_by": "ARRAY['id']",
}
)
}}
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'customers') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS id,
CAST(created_at AS TIMESTAMP) AS acc_created_at,
CAST(first_name AS VARCHAR) AS first_name,
CAST(last_name AS VARCHAR) AS last_name,
CAST(gender AS VARCHAR) AS gender,
CAST(country AS VARCHAR) AS country,
CAST(address AS VARCHAR) AS address,
CAST(phone AS VARCHAR) AS phone,
CAST(email AS VARCHAR) AS email,
CAST(payment_method AS VARCHAR) AS payment_method,
CAST(traffic_source AS VARCHAR) AS traffic_source,
CAST(referrer AS VARCHAR) AS referrer,
CAST(customer_age AS DECIMAL) AS customer_age,
CAST(device_type AS VARCHAR) AS device_type
from source
where row_num = 1
)
select * from deduped_and_renamed{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
incremental_strategy='merge',
unique_key='id',
properties={
"format": "'PARQUET'",
"partitioning": "ARRAY['category']",
"sorted_by": "ARRAY['id']",
}
)
}}
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'products') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS id,
CAST(name AS VARCHAR) AS name,
CAST(category AS VARCHAR) AS category,
CAST(price AS DECIMAL(10,2)) AS price,
CAST(description AS VARCHAR) AS description,
CAST(unit_shipping_cost AS DECIMAL(4, 2)) AS unit_shipping_cost
from source
where row_num = 1
)
select * from deduped_and_renamed{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
incremental_strategy='merge',
unique_key='id',
properties={
"format": "'PARQUET'",
"partitioning": "ARRAY['state']",
"sorted_by": "ARRAY['id']",
}
)
}}
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'stores') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS id,
CAST(name AS VARCHAR) AS name,
CAST(city AS VARCHAR) AS city,
CAST(state AS VARCHAR) AS state,
CAST(tax_rate AS DECIMAL(10, 8)) AS tax_rate
from source
where row_num = 1
)
select * from deduped_and_renamedIntermediate
Similar to the staging stage, we have the intermediate stage in the dbt/e2e_bi_tutorial/models/intermediate directory.
As with staging, you’ll notice we specify the sources and models in the int_iceberg.yml file.
version: 2
sources:
- name: int_iceberg
database: iceberg
schema: project_staging
tables:
- name: stg_iceberg__orders
- name: stg_iceberg__customers
- name: stg_iceberg__products
- name: stg_iceberg__stores
models:
- name: int_iceberg__denormalized_ordersThen we add the model SQL file int_iceberg__denormalized_orders.sql.
{{
config(
file_format='iceberg',
materialized='incremental',
on_schema_change='sync_all_columns',
unique_key='order_id',
incremental_strategy='merge',
properties={
"format": "'PARQUET'",
"sorted_by": "ARRAY['order_id']",
"partitioning": "ARRAY['device_type']",
}
)
}}
with denormalized_data as (
select
o.order_id,
o.order_created_at,
o.qty,
o.product_id,
o.customer_id,
o.store_id,
c.acc_created_at,
c.first_name,
c.last_name,
-- Concatenated columns
CONCAT(c.first_name, ' ', c.last_name) as full_name,
c.gender,
c.country,
c.address,
c.phone,
c.email,
c.payment_method,
c.traffic_source,
c.referrer,
c.customer_age,
c.device_type,
p.name as product_name,
p.category as product_category,
(p.price/100) as product_price,
p.description as product_description,
p.unit_shipping_cost,
s.name as store_name,
s.city as store_city,
s.state as store_state,
s.tax_rate,
-- Calculated columns
(p.price/100) * o.qty as total_product_price,
((p.price/100) * o.qty) + p.unit_shipping_cost as total_price_with_shipping,
(((p.price/100) * o.qty) + p.unit_shipping_cost) * (1 + s.tax_rate) as total_price_with_tax
from {{ ref('stg_iceberg__orders') }} o
left join {{ ref('stg_iceberg__customers') }} c
on o.customer_id = c.id
left join {{ ref('stg_iceberg__products') }} p
on o.product_id = p.id
left join {{ ref('stg_iceberg__stores') }} s
on o.store_id = s.id
)
select *
from denormalized_dataFinally in dbt/dbt_project.yml, we update the models configuration for the intermediate stage.
...
models:
e2e_bi_tutorial:
staging:
+materialized: view
+schema: staging
+views_enabled: false
intermediate:
+materialized: view
+schema: intermediate
+views_enabled: false
...Marts
Same deal with marts. We have the dbt/e2e_bi_tutorial/models/marts directory where we specify the sources and models in the mart_iceberg.yml file.
version: 2
sources:
- name: marts_iceberg
database: iceberg
schema: project_intermediate
tables:
- name: int_iceberg__denormalized_orders
models:
- name: marts_iceberg__general
- name: marts_iceberg__marketing
- name: marts_iceberg__paymentTake note of the Marts naming convention.
Add the Marts Models
{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
unique_key='order_id',
incremental_strategy='merge',
properties={
"format": "'PARQUET'",
"partitioning": "ARRAY['traffic_source']"
}
)
}}
with final as (
select * from {{ ref('int_iceberg__denormalized_orders') }}
)
select *
from final{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
unique_key='order_id',
incremental_strategy='merge',
properties={
"format": "'PARQUET'",
"partitioning": "ARRAY['traffic_source']"
}
)
}}
with final as (
select
order_id,
order_created_at,
qty,
product_id,
customer_id,
store_id,
traffic_source,
referrer,
product_name,
product_category,
product_description,
unit_shipping_cost,
store_name,
store_city,
store_state,
tax_rate,
total_price_with_shipping,
total_price_with_tax,
product_price,
total_product_price
from {{ ref('int_iceberg__denormalized_orders') }}
)
select *
from final{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
unique_key='order_id',
incremental_strategy='merge',
properties={
"format": "'PARQUET'",
"partitioning": "ARRAY['payment_method']"
}
)
}}
with final as (
select
order_id,
order_created_at,
product_id,
qty,
unit_shipping_cost,
tax_rate,
total_price_with_shipping,
total_price_with_tax,
product_price,
total_product_price,
payment_method
from {{ ref('int_iceberg__denormalized_orders') }}
)
select *
from finalFinally, we update the models configuration for the marts stage in dbt/dbt_project.yml.
...
models:
e2e_bi_tutorial:
staging:
+materialized: view
+schema: staging
+views_enabled: false
intermediate:
+materialized: view
+schema: intermediate
+views_enabled: false
marts:
+materialized: view
+schema: marts
+views_enabled: false
...Why These Specific Marts?
We have three marts here: general, marketing, and payment. Why these specific Marts?
We typically create Marts for specific data consumer groups.
general: This is the most general mart. It contains all the data from the intermediate stage. This is typically used by anyone who wants denormalized wide table data for analysis.marketing: This mart contains data that is useful for the marketing team. For example, it contains data on traffic sources, referrers, etc.payment: This mart contains data that is useful for the payment team. For example, it contains data on payment methods.
Run the DBT Models
Now we can run dbt build to run all the models we’ve created.
Before we do that, make sure all other docker services are running.
In the project root directory, run:
Move back into the dbt project directory.
There’s one more thing we need to do before we can run the models - we have to run dbt parse to generate the manifest file when we run DBT for the first time.
DBT Parse
Make sure you’re in the inner project directory of the DBT project (where the dbt_project.yml file is) and run:
Learn more about the dbt parse command here.
OK, now we’re ready to run the DBT models!
DBT Build
You should see all the models being built successfully.
Check the Transformation Results
Now that we’ve run the DBT models, let’s check the results in the Trino shell.
Let’s first set the catalog and schema to project_marts so we can query the tables in that schema.
Here’s how we can set the schema in Trino shell:
Where is this schema name from? We’ve covered it briefly above, but as a reminder, it comes from the combination of custom schema we set in the profiles.yml file and the schema we set for each model in dbt_project.yml.
dbt_project:
target: trino
outputs:
trino:
type: trino
...
schema: project
......
models:
e2e_bi_tutorial:
staging:
+materialized: view
+schema: staging
+views_enabled: false
intermediate:
+materialized: view
+schema: intermediate
+views_enabled: false
marts:
+materialized: view
+schema: marts
+views_enabled: false
...DBT prefixes individual model schemas with the custom schema, so the final schema name is project_staging, project_intermediate, and project_marts.
Note that raw schema doesn’t have the prefix because it was created outside of DBT (i.e. during Meltano ingestion).
Now we can query the table in the project_marts schema!
_col0
--------
100000
(1 row)Yes! It worked correctly.
Let’s also see the first 5 rows in the marts_iceberg__marketing table.
order_id | order_created_at | qty | product_id | customer_id ...
----------+----------------------------+-----+------------+------------ ...
12399 | 2022-12-23 00:00:00.000000 | 5 | 588 | 5630 ...
14244 | 2023-10-16 00:00:00.000000 | 3 | 511 | 3401 ...
16566 | 2023-08-03 00:00:00.000000 | 4 | 377 | 19243 ...
1817 | 2023-04-22 00:00:00.000000 | 7 | 929 | 12196 ...
18702 | 2023-01-07 00:00:00.000000 | 2 | 1873 | 1702 ...
(5 rows)Great! Everything seems to be working as expected.
You can press q to get out of the table view by the way.
When you’re done playing around with the tables, you can exit the Trino shell by typing exit;.
Clean Up
You can stop and remove all the docker services:
Conclusion
In this post, we set up DBT, connected it to Trino, and then wrote DBT models to transform our raw data.
We also learned about the three stages of data transformation - Staging, Intermediate, and Marts - and built some example DBT models for each stage.
Throughout this process, we were able to transform the raw data into business-conformed data ready for analytics.
In the next post, we’ll set up Superset and connect it to Trino to visualize the data we’ve transformed.
See you in the next post!
Questions and Feedback
If you have any questions or feedback, feel free to join us on Slack and we’ll do our best to help!